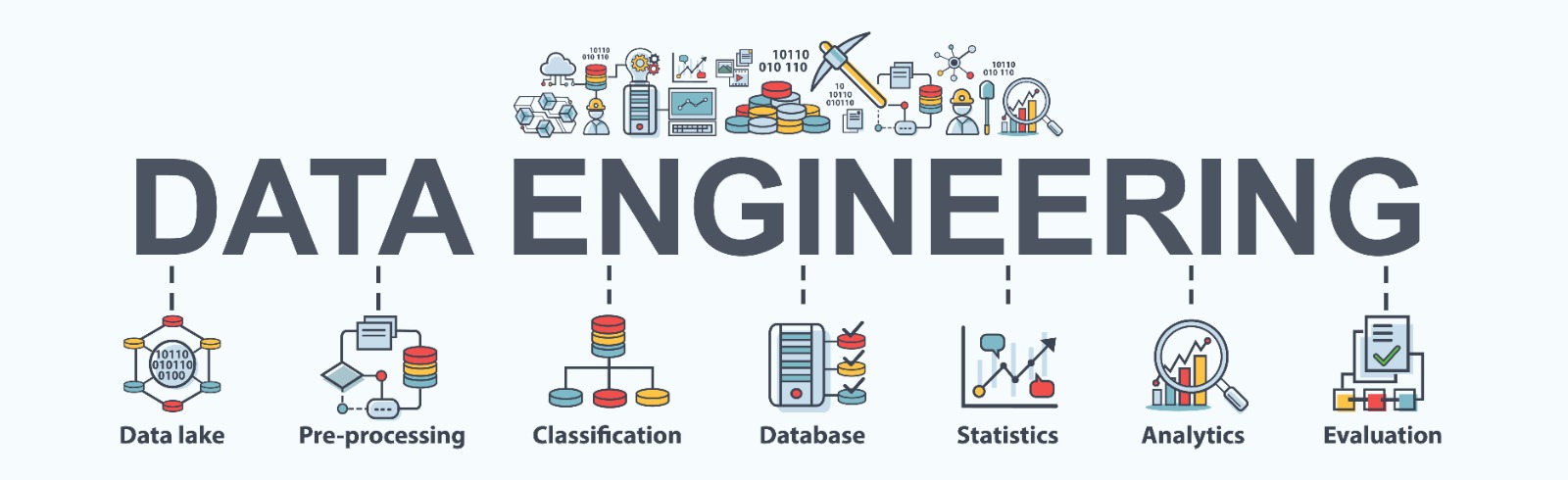
Data engineering is a process that designs and builds pipelines that transform and transport data, ensuring that it is clear, understandable and usable by the time it reaches the end user. Here are the seven stages of the data engineering process.
Data Lake
A data lake is a large and open storage location. It will usually make use of object storage as a repository for unstructured data. Data can come from a number of sources including operational and transactional data.
Pre-Processing
Once you have data in your data lake, you need to process it. Data preprocessing will help you to clean and prepare raw data. This is the stage where data engineers essentially get data ready for the data scientists to use.
Classification
Next, it’s time to classify the data you’ve designated for use. You will need to process tags and put your data into categories so that it can be more easily understood and analysed.
Database
The database is where your classified data will be stored. This system needs to be as secure as possible to keep your data safe.
Statistics
You can now analyse and interpret your data. This stage of the process will generally incorporate applied mathematics. You may, at this stage, begin to be able to draw small conclusions.
Analytics
Now, let’s analyse your data. Analytics helps you to identify important patterns in your data, such as trends, positive periods, negative periods and more.
Evaluation
Once you’ve drawn conclusions from the analysis process, you can really evaluate your data and determine what you need to do to improve your operations and processes!